
CIVET Workspaces¶
CIVET is part of a projected collection of open-source programs designed to work with very large sets of small text files: in the domain of contentious politics these are usually news articles but the issue of managing very large databases of small texts extends well beyond this application. For example, projects analyzing texts from legislative debates, legislation, campaign web sites and blogs all have much the same character when they are studied at a large scale.
In the CIVET system, files containing sets of individual stories are called “collections”: these are typically multiple related news stories—“texts”—from which one or more data records—“cases”—are coded. These are stored in a YAML format [1] which is a structured human-readable text file containing a number of data fields; the details of this are given in Appendix 2.
Sets of text collections are grouped into “workspaces” that also contain
an associated coding form and, optionally, other information such as
user-specified categories that will be used in automatic annotation. The
template file begins with the string “form.” and uses the category
and template commands described in the chapter CIVET Coding Form Templates.
Workspaces are compressed (.zip) directories (folders).
In the current configuration of the system, workspace files are uploaded to the system, annotated and/or coded, then downloaded when a session is completed: no data remain on the machine where the CIVET system is running. In a future version, we expect to have an option for persistent data that could be used on a secure server, as well as options for reading these files from a server.
The workspace will generally not be downloaded to the same place it
was originally: as a standard HTML security feature, the system does not
retain any information about where it obtained a file. Instead, it will
be downloaded to wherever your system downloads file: for example on the
Macintosh this is a folder named Downloads. [2] If you wish to
replace the original workspace file, this will need to be done manually
or with a script operating locally.
There is some limited error checking as the workspace is processed. If errors are found you will get a screen similar to the figure below listing the errors, which must be corrected before the workspace can be used.
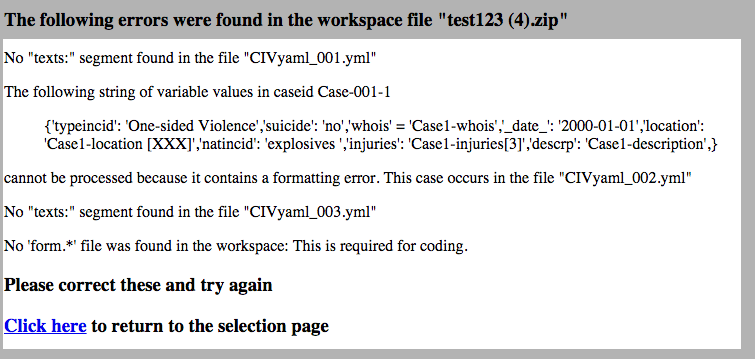
Like error messages in all programs, these are self-explanatory [3] though in general errors will occur either when you are processing a workspace for the first time or if you have manually edited it outside of the CIVET system: once a workspace has been successfully read by CIVET the program should not introduce any errors that would be caught at this point. [4]
The program is sensitive to file names:
- Any file ending with
.ymlis assumed to be a CIVET -formatted collections file - There should be one and only file beginning with the string
form.: this specifies the coding form for the workspace - Any file beginning with
codes.is assumed to be a category vocabulary list. In the file name, “codes.” must be followed by acategoryname then a period; the remainder of a “codes” file name can be anything, though typically it will end in.txt. - Any file ending with
.iniis assumed to be a configuration file [Version 1.0: Not yet implemented—see comments on setting globals in the “Preferences” chapter.]
Except for these restrictions, the directory can contain additional files of any kind: these will be preserved when the file is downloaded. A workspace file cannot contain subdirectories.
Additional notes on workspaces:
- So long as the YAML formatting is preserved—which should be fairly straightforward—the system is indifferent as to whether editing is done inside or outside of CIVET .
- If the
formfile is missing or contains errors, the system will display the errors it found, then return to the data selection page. - If you are manually editing the variable values in the
casessection, any single quotes (’) must be “escaped”; that is, replaced with\’. This will be done automatically when cases are generated from inside the program. - The system currently translates UTF-8 encodings to ASCII [5] using the
Django function
encoding.smart_str(). We expect to eventually convert the program to Python 3.x (at present it is Python 2.7) which is utf-8 “native” but it isn’t there yet.
Workspace Management¶
The Manage workspace link on the home page will take you first to a
workspace selection page, and then to the page shown below. In Beta 0.9, only the
Export data in tab-delimited format/Use save-variable list in the template
is implemented: this will download any coded cases found in the
workspace. The remaining functions will eventually be implemented but in
the meantime these tasks can be done using a text editing program.

User-specified annotation vocabulary using category¶
The category command is used to set up special categories of words
that will be color-coded and can be associated with text-extraction
fields. The annotation can either be done automatically or by manually
selecting the text and using the Style pull-down menu in the
annotation editor.
category: category-name [color]comma-delimited-phrase/code-list or file-name
The category-name must be unique and cannot be one of the standard
categories nament, num or date. The program currently
accommodates up to 99 categories. [6]
color can be any of the 140 named HTML5 colors, [7] a six-digit
hexadecimal RGB color (e.g. 6A5ACD corresponds to the named color
“SlateBlue”; the hex notation provides a presumably sufficient choice
of 16,777,216 colors), or a two-digit color from the CIVET
palette. [8] The palette, shown below, can be
accessed by entering the address[color] is
empty—that is, []—the system uses a color from the standard list
in the listed order.
Automatic annotation/skip editing mode only:¶
When the program is running with Always apply annotation: True and
Skip editing: True, [9] categories can be further visually differentiated using
one or more of the following font specifications
- bold: bold face
- italic: italic
- under: underline
So for example [Green bold italic] will display the category in an
italic bold font colored green.
Additional information on categories¶
1. Generally, matching of words and phrases is not case sensitive: in the example below, both “killed” and “Killed” will match. However, if the word in the category list is all uppercase—e.g. NATO, IRA, ISIS—it will only match all-uppercase strings: this should deal with most cases of acronyms, in particular US and IS. A word or phrase can only be in a a single category: putting one in multiple categories will not cause an error, but only the first category evaluated—generally this will occur in the order the categories were entered—will be marked. Words and phrases within a category are evaluated in the order they are listed—see the example in the chapter on annotation— which can be used to establish precedent when words or phrases overlap. At present the program does not allow partial matches, though a facility for this may be added in the future. [10]
2. The comma-delimited-phrase/code-list can have codes assigned to each of the phrases: these occur in brackets following the phrase and are added to the text during automated markup. The codes can be any character string. Either the phrase or the code or both can be specified in the output. If some of the phrases in the list have codes and others do not, the blank codes will be assigned a null (or, optionally, missing) string.
3. The vocabulary list can also be read from a file in the workspace. The
file name must begin with codes.category-name.; the remainder of
the file name can be anything. [11] This be a text file with one phrase
per line and the code in brackets; a line beginning with # is treated as
a comment.
- As with texts, UTF-8 encodings are translated to ASCII using the
Django function
encoding.smart_str().
Example:
category:action [red italic]
killed [1], wounded [2], shot and killed [1], bombed [3], clashed [3]
category:people [Brown]
civilians, workers, authorities, troops, soldiers, rebels, people, group``
category:nationstate [Gold bold under]
codes.nationstate.txt
category:weapons [Olive]
codes.weapons.mnsa.weaponslist_150724.txt
Footnotes
| [1] | https://en.wikipedia.org/wiki/YAML |
| [2] | If you read the workspace from the same directory where it will eventually be downloaded, the behavior presumably depends on the operating system: in the case of OS-X both the downloaded file and the decompressed versions get a suffix added. E.g. if the original workspace folder is named “test123” with the compressed version “test123.zip”, the system assigns the downloaded version the name “test123 (1).zip” which decompressed to a folder named “test123 (1)”. We are leaving the task of insuring that the original file is not over-written to the operating system and whatever other utilities you might be using to manage workspaces. |
| [3] | Hahaha…just a little programmer joke… |
| [4] | For example, the error in the variable values string in the example screen
occurs because of the substring
'whois'='Case1-whois', which should actually be
'whois':'Case1-whois', but that ‘=’ could only have been
introduced through external editing. |
| [5] | UTF-8 is an expanded UniCode character set that includes accented letters, “smart quotes” and many many more characters not found in the older ASCII (American Standard Code for Information Interchange) character set. UTF-8 is very widely used on the Web so if you have downloaded texts, there’s a pretty good change they contain at least some UTF-8 characters. |
| [6] | If you need more, this can be changed by allowing more digits in
the {:02d} format in the code
UserCategories[newcat].append('termst{:02d}'.format(len(UserCategories)))
in CIVET_template.make_category() |
| [7] | See http://www.w3schools.com/html/html colornames.asp |
| [8] | This palette was assembled in a very ad hoc manner, is not
color-blind-friendly, and we would be delighted to substitute
something better. The list is set as CIV_template.CatColorList |
| [9] | This is the configuration typically used when just coding the texts with automated annotation. We plan to retrofit this to the editor as well but adding it to the annotation was a simple hack, and adding it to the editor is a little more complicated. |
| [10] | If you want it now, delete the test if endx == idx+len(st): in
CIVET_utilities.do_string_markup(). |
| [11] | The period following the category-name is required!: the file name
codes.weapons_mnsa_list.txt would not be recognized as a valid
codes. file. Or rather it would be interpreted as applying to a
category weapons_mnsa_list, not the category weapons. |